

Abstract: In this piece, BitMEX grantee Calvin Kim explains why the order in which blocks are validated does not matter under Utreexo. This is because the disk space savings make UTXO snapshots practical, which in turn allows for the parallelisation of the validation of the Bitcoin Blockchain. Calvin goes on to explain that one can check if an incoming transaction is valid by verifying the accumulator proof, getting rid of the need to access the UTXO set. This allows Utreexo nodes to eliminate disk access requirements, in exchange for more hashing, which can be an excellent trade-off. Calvin then discusses how Utreexo can change how we think about block validation.
In a separate post, we’ve shown benchmarks on the speed differences in Blockchain validation between Bitcoin Core v21.0.0 and our node with Utreexo Accumulators. We’re able to do this as Utreexo Accumulators allow for the parallel validation of blocks.
The general idea is similar to that of the assumeUTXO-style asynchronous validation. With Utreexo Accumulators however, we can represent the UTXO set in a couple hundred bytes, allowing us to hardcode many representations of UTXO sets directly into the binary. As long as all of these hardcoded sets are validated, the order in which blocks are validated does not matter, allowing us to validate multiple blocks at the same time. Utreexo Accumulators also replace disk access for more SHA256 hashing, removing disk i/o bottlenecks that would have occurred without it.
Validating a single transaction with Utreexo Accumulators
Utreexo Accumulators is a modification of Merkle Trees. Its interface has four actions: add, remove, prove, verify. You can add and remove elements from the Utreexo Accumulators. You can generate an accumulator proof to prove to a user that an element exists. Another user is then able to validate such an accumulator proof. All of these actions can be done with just the roots of all Merkle Trees which we call Utreexo Roots. For more information, check out the original Utreexo paper.
With a Bitcoin Node using Utreexo Accumulators, we don’t have to keep a UTXO set. Instead, we can just keep the Utreexo Roots as this is the only requirement. Anyone that wants to spend their UTXO must provide us with two things. First, they must provide an accumulator proof, which is all the elements that are required to hash up to the Utreexo Roots. Second, they must provide UTXO data to prove they are able to spend the UTXO (mainly digital signatures). We call this information a Utreexo Proof.
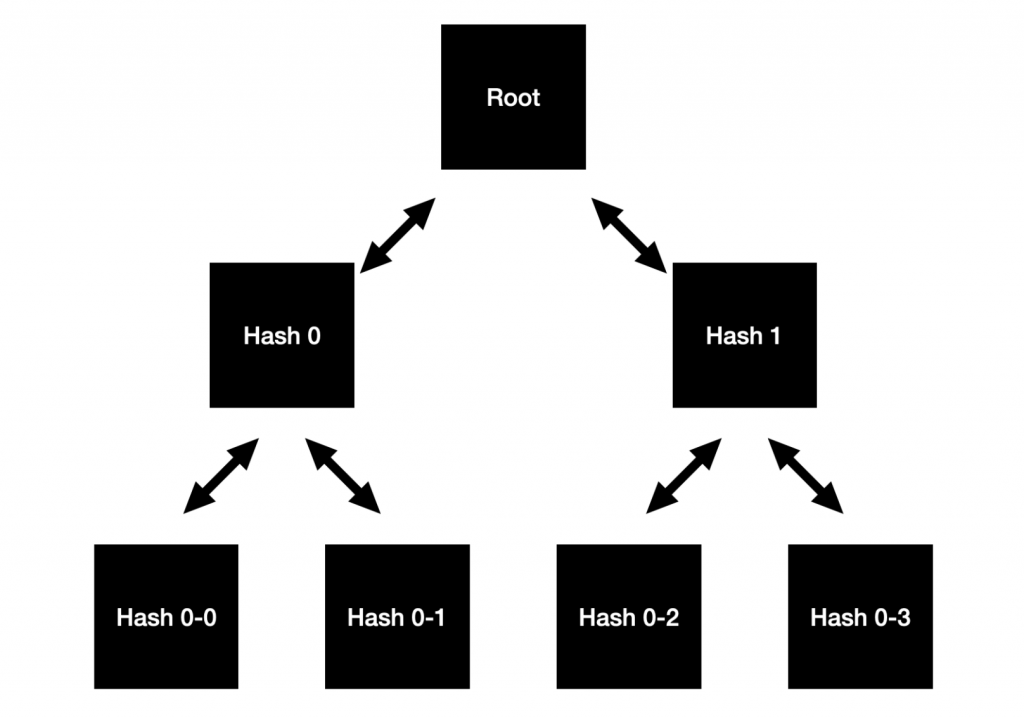
The Utreexo Proof for Hash 0-0 in the above tree would be: Hash 0-0, Hash 0-1, Hash 1. To verify this proof, we do the following:
- Put Hash 0-0 and Hash 0-1 into SHA256 and get Hash 0
- Put Hash 0 (that we calculated) and Hash 1 into SHA256 to get the Root.
- Check if the calculated Root matches the Root we stored. If it doesn’t match, the Utreexo Proof is wrong and we reject the transaction.
- Check all the UTXO data. If any data isn’t valid, the Utreexo Proof is wrong and we reject the transaction.
How is a single block verified with Utreexo Accumulators?
To verify a single block with Utreexo Accumulators, these are the required data:
- Data of the block itself.
- Utreexo Proof of all the UTXOs being spent in the block.
- Roots of the UTXO set.
We receive the data of the block from our peers. The difference is that we also receive a Utreexo Proof for the block we received. The validity of a block depends on (among other consensus rules) the validity of all the transactions in the block.
Validity of a single transaction for a Utreexo node is dependent on the validity of the Utreexo Proof which consists of two things:
- The validity of the accumulator proof.
- The validity of the digital signature proving that you own the UTXO (or UTXOs).
Notice that (1) is different. In the current Bitcoin nodes, you had to check if the UTXO existed in your UTXO set. This requires accessing the disk. With Utreexo nodes, you just verify the accumulator proof and make sure it’s valid. This requires SHA256 hashing. The key thing to note is that with Utreexo Accumulators, we can replace disk access for SHA256 hashing.
Utreexo Accumulators eliminate disk access for more SHA256 hashing during tx validation
This tradeoff is fantastic as SHA256 can be done extremely quickly. Disk access times are slow in comparison (even with the fastest NVMe SSDs) and are not getting much faster.
Shifting how we think about Block validation
Many think of the Blockchain as where all the coins available to be spent are stored. However, this is not entirely accurate. The information needed to verify a new block or transaction is stored in the UTXO set. In fact, we already have a Bitcoin full node mode called pruned nodes, that delete old, unneeded block data.
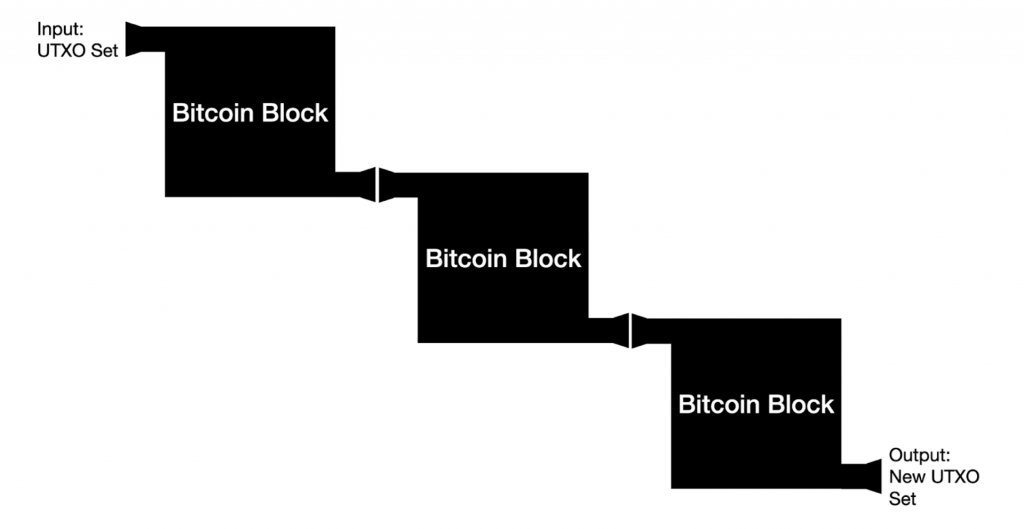
Instead, blocks are a mere function that changes the UTXO set. Each block contains information on the change of ownership of many UTXOs. All past blocks are all the change of ownerships that are needed to get to the latest state of the UTXO set. When we’re verifying a block, what we’re really doing is making sure the state transition of the UTXO set is valid.

If a Bitcoin Block is a single state transition of the UTXO set, then a chain of blocks are multiple state transitions of the UTXO set. Below is what a representation of the Bitcoin Blockchain would look like if we look at the Blockchain as a series of UTXO set modifications.
Why do we need to verify all the blocks sequentially?
The reason we need to start from block 0 and verify all the blocks one-by-one is because a transaction at block 500 can be referencing a UTXO created at block 499. If we don’t have the state of the UTXO set after block 499 modification happened, then we can potentially mark a valid transaction as invalid and be forked off the Bitcoin network.
For example, if Alice gave Bob 50 Bitcoins and that transaction was included in block 499, Bob will have to refer to the UTXO set after the modification at block 499. If our UTXO set has not had the modification at block 499, then we’ll wrongly state that the 50 Bitcoin in question still belongs to Alice, not Bob. When Bob spends his 50 Bitcoins, everyone else will say Bob’s transaction is valid while we’ll say it isn’t. This will result in us being forked off the Bitcoin Network.
The general idea for Out of Order Block Validation
We know that a full node has to verify all the blocks, one-by-one, from the beginning. So how is it then that we’re able to do an Out of Order Block Validation? For an Out of Order Block Validation, we could simply provide the UTXO set needed to validate a block. This is the idea behind assumeUTXO asynchronous validation.
Let’s look at a simple example of an Out of Order Block Validation where we’re verifying blocks 1-300,000.
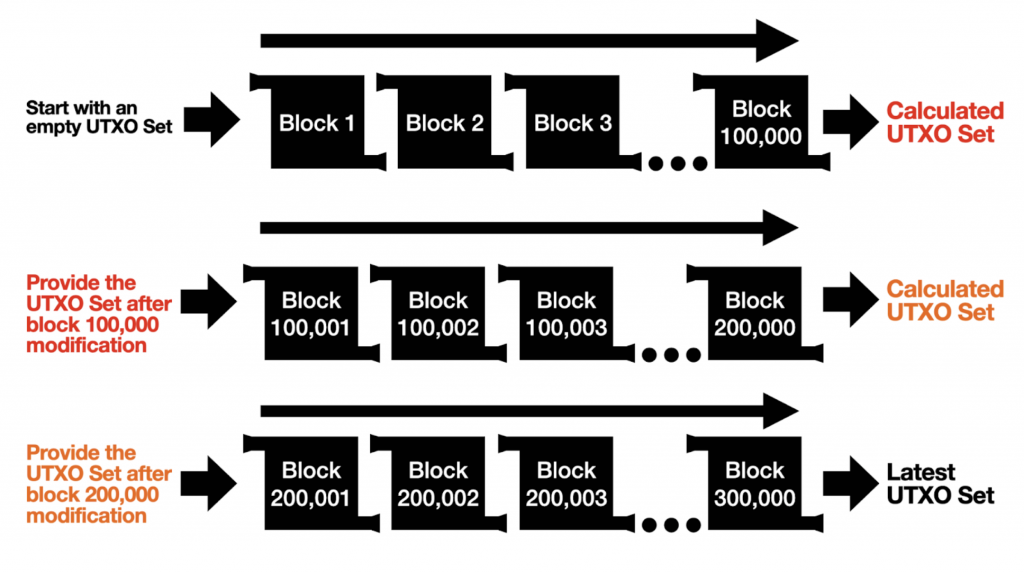
We hardcode the UTXO set at height 100,000 and 200,000. Since we know what the UTXO sets at height 100,000 and 200,000 are we can separately validate the block ranges 1-100,000; 100,000-200,000; and 200,000-300,000. When all three ranges have finished validating, we’ll have three calculated UTXO sets: one at block 100,000; one at block 200,000; and one at block 300,000.
We then compare the hardcoded UTXO set at block 100,000 with the calculated UTXO set at block 100,000. If they are equal, then the hardcoded UTXO set is verified to be correct. We do the same for the UTXO sets at block 200,000. If they are also equal, then we know that the latest UTXO set after the block 300,000 modification must be correct. With this concept, we can have an Out of Order Block Validation.
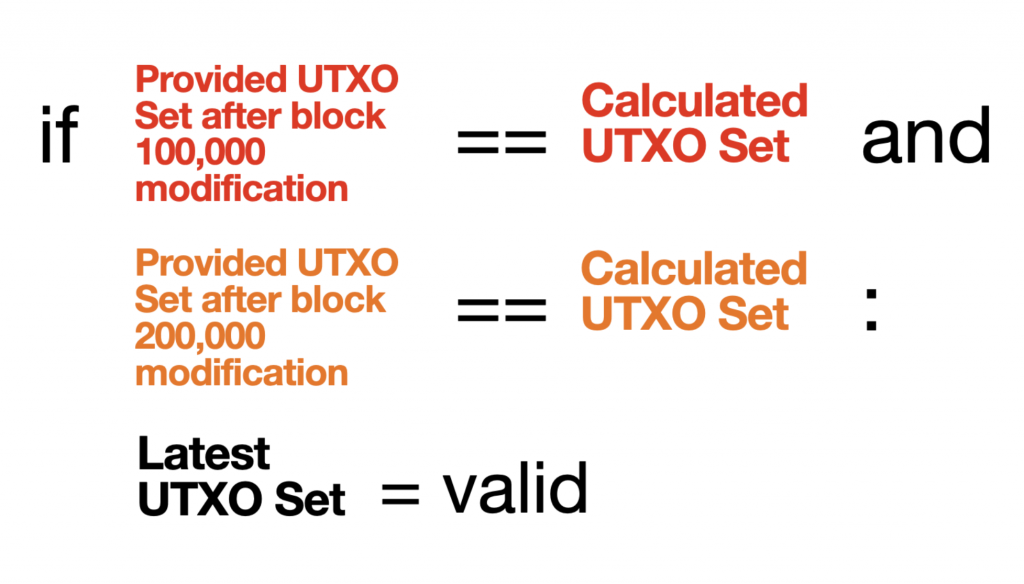
If we hardcode all the UTXO sets at every block, we are able to validate any block at any height in any given order.
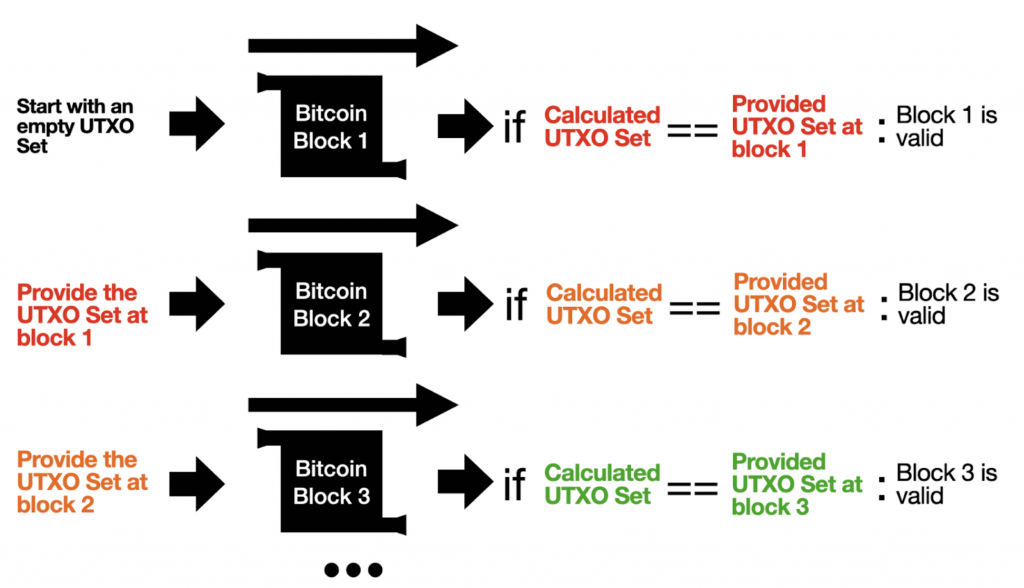
The Block validation function can be simplified to look like so:

The Start UTXO set and the End UTXO set are the UTXO sets at block height n and n+1. Block Data is the data of the block at height n that we’ll be verifying. Rules are the necessary chain rules for that block height. New rules are introduced through soft forks so they must also be included in this function. Rules include: whether or not Segwit rules are activated, whether or not Taproot rules are activated, etc.
The need for Utreexo Accumulators
There are two reasons why Utreexo Accumulators are needed for this type of block validation.
- Utreexo is tiny.
- Utreexo eliminates disk access.
- Utreexo is tiny
The Out of Order Block Download is theoretically doable without Utreexo Accumulators. However, since the UTXO set is over 4GB in size, it’s practically infeasible as you need to provide a lot of UTXO sets to verify the entire Blockchain. To verify each block in the chain, one would need 8GB of data. This quickly adds up (100 blocks need 800GB) and makes it impossible to hardcode into the binary.
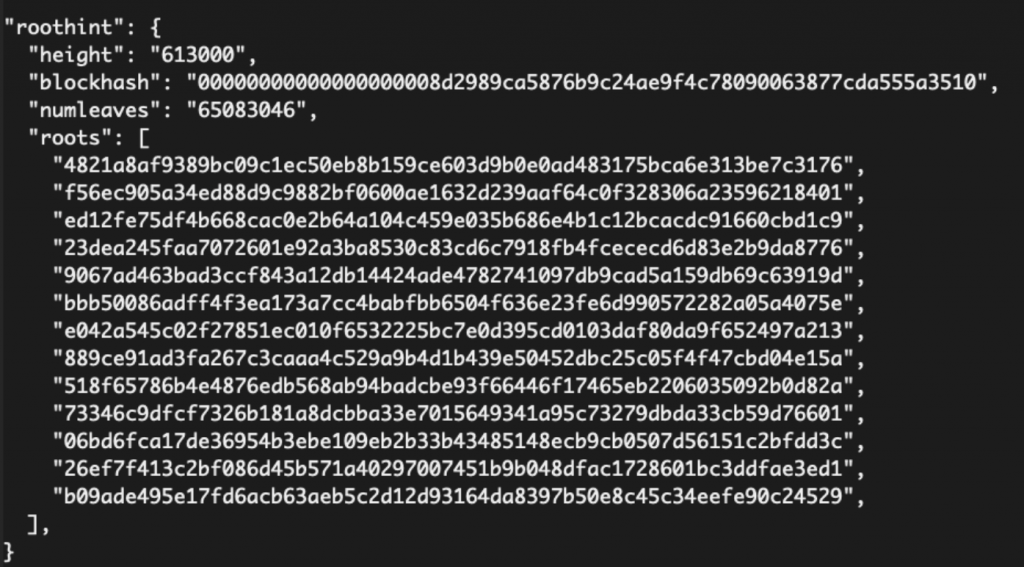
With Utreexo Accumulators, this becomes feasible as we can represent the UTXO set in a few hundred bytes. Here’s an example of an actual hardcoded Utreexo Roots in json:
We can then modify the Block validation function to use Utreexo Accumulators instead. The Block validation function would look like so:

The Start Utreexo Roots and the End Utreexo Roots are equivalent to the UTXO Sets at height n and n+1. Utreexo Proof is added to be able to verify the Block Data.
- Utreexo eliminates disk access for more SHA256 hashing
With Utreexo Accumulators, we’re able to solve the size problem. However, that’s not the only problem that Utreexo Accumulators solve. Utreexo Accumulators eliminate disk access for more SHA256 hashing. This is extremely important as without Utreexo Accumulators, you’d be disk i/o bottlenecked.
With UTXO sets, a transaction verification would depend on fetching the required UTXO from disk. This would be a tiny random disk access and we know that tiny random disk accesses are not fast. For a block verification, there are many tiny random disk accesses. For a parallel block verification, the number of these tiny random disk accesses would skyrocket. There are no SSDs that can keep up with this demand.
Utreexo eliminates disk access for more SHA256 hashing during transaction validation. Since a block is a collection of transactions, Utreexo also eliminates disk access for more SHA256 hashing during block validation. Therefore, verifying a block essentially becomes calculating SHA256 hashes(among checking for other consensus rules). A Blockchain is just a series of blocks, so verifying the entire Blockchain requires no disk access but more SHA256 hashing instead. Thus the IBD process would result in tons of SHA256 hashes being calculated. This is ok because we know how to calculate SHA256 hashes extremely quickly.
Because of these reasons, Utreexo Accumulators are essential in a parallel Blockchain validation. Utreexo Accumulators solve two big problems at the same time and enable parallel Blockchain validation to be done.
Conclusion
Over time, the amount of data that needs to be validated in a Blockchain goes up. It is critical to offset the increase in data to be validated with software optimizations to keep the IBD minimized as an entry barrier. With Utreexo Accumulators we’re able to do this. With more optimizations with Utreexo Accumulators left to be explored, I’m extremely excited for future research and the potential that Utreexo Accumulators can have on the Bitcoin ecosystem. You can join us in our cause at github.com/mit-dci/utreexo.


















{kind=link}