
Groq’s LPU Inference Engine, a dedicated Language Processing Unit, has set a new record in processing efficiency for large language models.
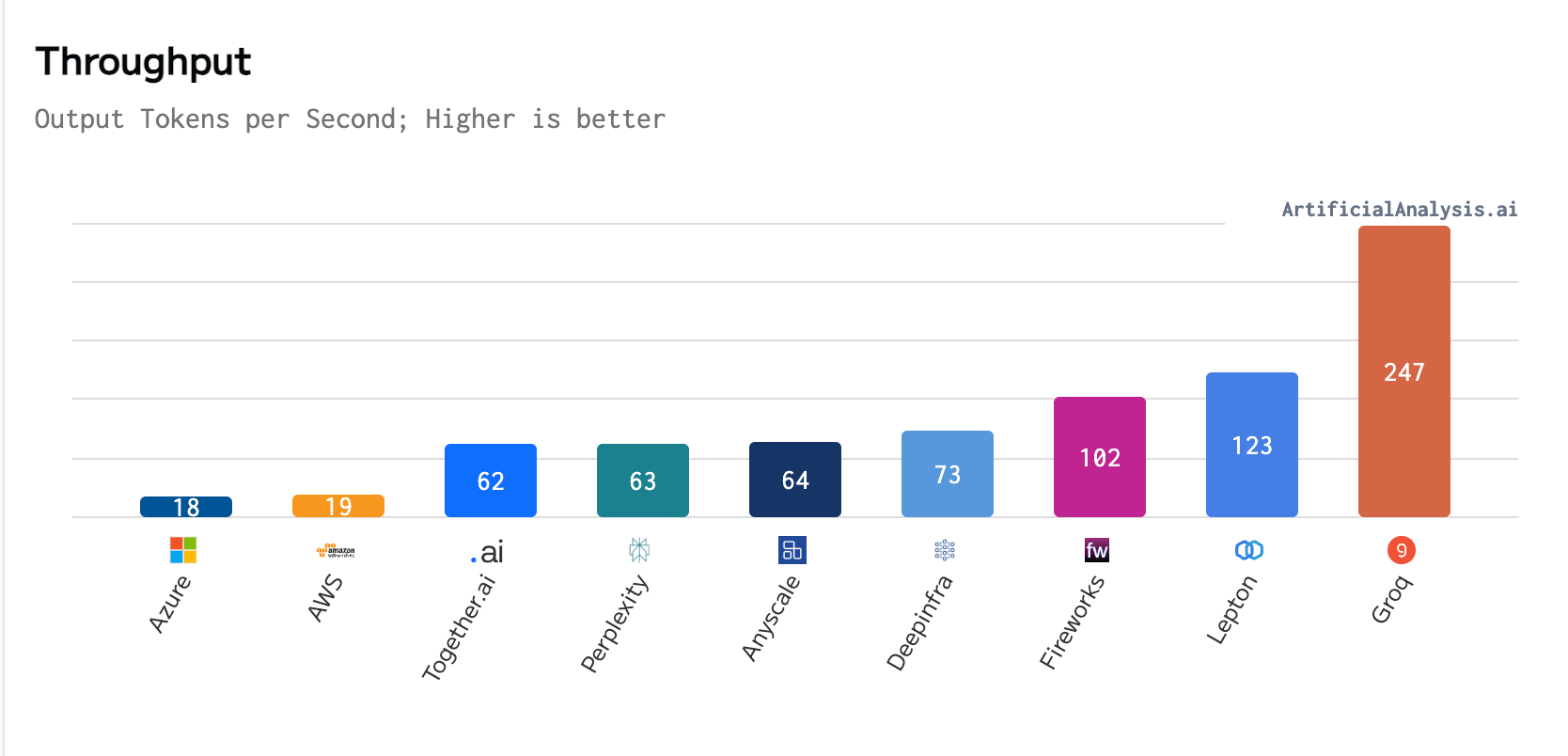
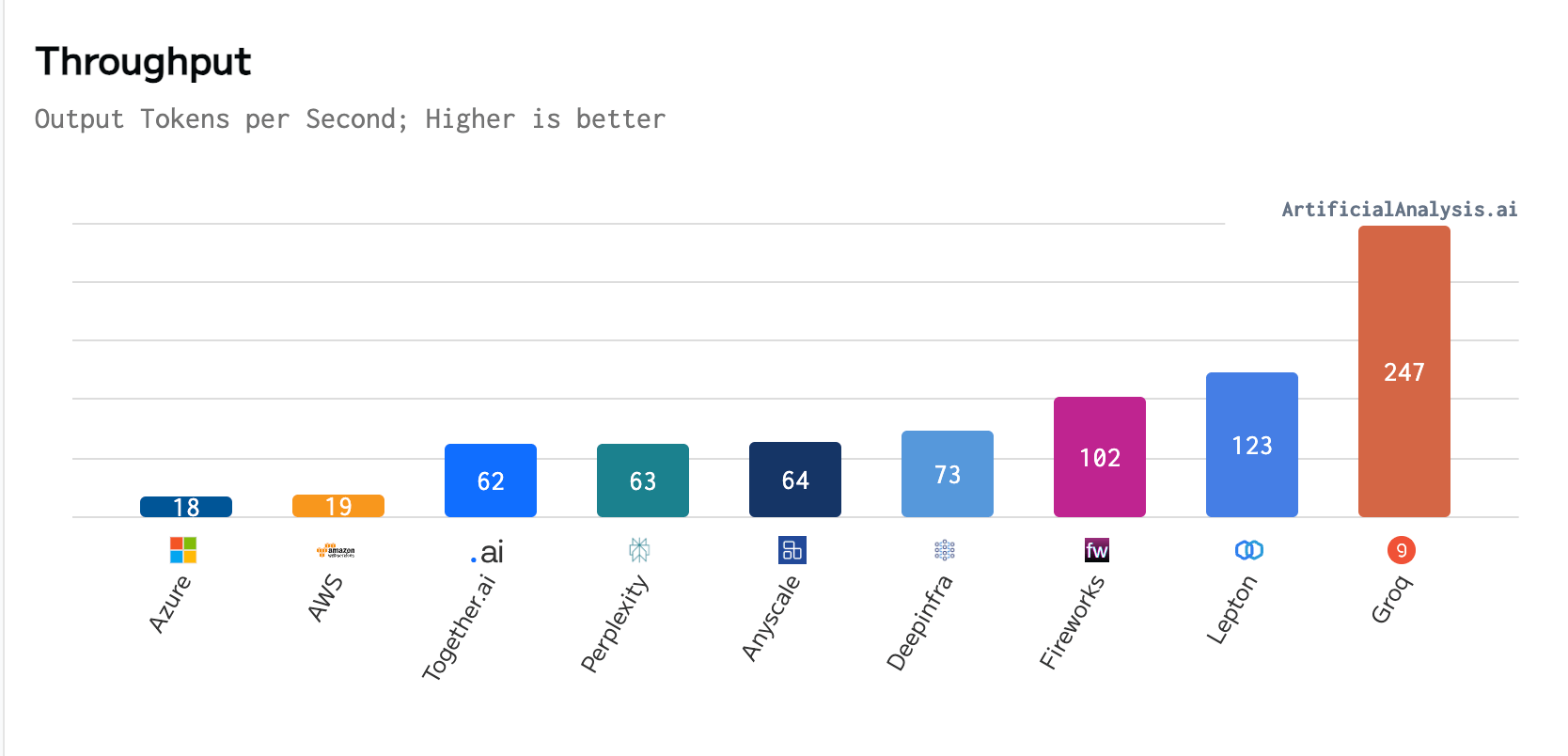
In a recent benchmark conducted by ArtificialAnalysis.ai, Groq outperformed eight other participants across several key performance indicators, including latency vs. throughput and total response time. Groq’s website states that the LPU’s exceptional performance, particularly with Meta AI’s Llama 2-70b model, meant “axes had to be extended to plot Groq on the latency vs. throughput chart.”
Per ArtificialAnalysis.ai, the Groq LPU achieved a throughput of 241 tokens per second, significantly surpassing the capabilities of other hosting providers. This level of performance is double the speed of competing solutions and potentially opens up new possibilities for large language models across various domains. Groq’s internal benchmarks further emphasized this achievement, claiming to reach 300 tokens per second, a speed that legacy solutions and incumbent providers have yet to come close to.
The GroqCard Accelerator, priced at $19,948 and readily available to consumers, lies at the heart of this innovation. Technically, it boasts up to 750 TOPs (INT8) and 188 TFLOPs (FP16 @900 MHz) in performance, alongside 230 MB SRAM per chip and up to 80 TB/s on-die memory bandwidth, outperforming traditional CPU and GPU setups, specifically in LLM tasks. This performance leap is attributed to the LPU’s ability to significantly reduce computation time per word and alleviate external memory bottlenecks, thereby enabling faster text sequence generation.
Accelerator, priced at $19,948 and readily available to consumers, lies at the heart of this innovation. Technically, it boasts up to 750 TOPs (INT8) and 188 TFLOPs (FP16 @900 MHz) in performance, alongside 230 MB SRAM per chip and up to 80 TB/s on-die memory bandwidth, outperforming traditional CPU and GPU setups, specifically in LLM tasks. This performance leap is attributed to the LPU’s ability to significantly reduce computation time per word and alleviate external memory bottlenecks, thereby enabling faster text sequence generation.

Comparing the Groq LPU card to NVIDIA’s flagship A100 GPU of similar cost, the Groq card is superior in tasks where speed and efficiency in processing large volumes of simpler data (INT8) are critical, even when the A100 uses advanced techniques to boost its performance. However, when handling more complex data processing tasks (FP16), which require greater precision, the Groq LPU doesn’t reach the performance levels of the A100.
Essentially, both components excel in different aspects of AI and ML computations, with the Groq LPU card being exceptionally competitive in running LLMS at speed while the A100 leads elsewhere. Groq is positioning the LPU as a tool for running LLMs rather than raw compute or fine-tuning models.
Querying Groq’s Mixtral 8x7b model on its website resulted in the following response, which was processed at 420 tokens per second;
“Groq is a powerful tool for running machine learning models, particularly in production environments. While it may not be the best choice for model tuning or training, it excels at executing pre-trained models with high performance and low latency.”
A direct comparison of memory bandwidth is less straightforward due to the Groq LPU’s focus on on-die memory bandwidth, significantly benefiting AI workloads by reducing latency and increasing data transfer rates within the chip.
Evolution of computer components for AI and machine learning
The introduction of the Language Processing Unit by Groq could be a milestone in the evolution of computing hardware. Traditional PC components—CPU, GPU, HDD, and RAM—have remained relatively unchanged in their basic form since the introduction of GPUs as distinct from integrated graphics. The LPU introduces a specialized approach focused on optimizing the processing capabilities of LLMs, which could become increasingly advantageous to run on local devices. While services like ChatGPT and Gemini run through cloud API services, the benefits of onboard LLM processing for privacy, efficiency, and security are countless.
GPUs, initially designed to offload and accelerate 3D graphics rendering, have become a critical component in processing parallel tasks, making them indispensable in gaming and scientific computing. Over time, the GPU’s role expanded into AI and machine learning, courtesy of its ability to perform concurrent operations. Despite these advancements, the fundamental architecture of these components primarily stayed the same, focusing on general-purpose computing tasks and graphics rendering.
The advent of Groq’s LPU Inference Engine represents a paradigm shift specifically engineered to address the unique challenges presented by LLMs. Unlike CPUs and GPUs, which are designed for a broad range of applications, the LPU is tailor-made for the computationally intensive and sequential nature of language processing tasks. This focus allows the LPU to surpass the limitations of traditional computing hardware when dealing with the specific demands of AI language applications.
One of the key differentiators of the LPU is its superior compute density and memory bandwidth. The LPU’s design enables it to process text sequences much faster, primarily by reducing the time per word calculation and eliminating external memory bottlenecks. This is a critical advantage for LLM applications, where quickly generating text sequences is paramount.
Unlike traditional setups where CPUs and GPUs rely on external RAM for memory, on-die memory is integrated directly into the chip itself, offering significantly reduced latency and higher bandwidth for data transfer. This architecture allows for rapid access to data, crucial for the processing efficiency of AI workloads, by eliminating the time-consuming trips data must make between the processor and separate memory modules. The Groq LPU’s impressive on-die memory bandwidth of up to 80 TB/s showcases its ability to handle the immense data requirements of large language models more efficiently than GPUs, which might boast high off-chip memory bandwidth but cannot match the speed and efficiency provided by the on-die approach.
Creating a processor designed for LLMs addresses a growing need within the AI research and development community for more specialized hardware solutions. This move could potentially catalyze a new wave of innovation in AI hardware, leading to more specialized processing units tailored to different aspects of AI and machine learning workloads.
As computing continues to evolve, the introduction of the LPU alongside traditional components like CPUs and GPUs signals a new phase in hardware development—one that is increasingly specialized and optimized for the specific demands of advanced AI applications.
The post Groq’s $20,000 LPU chip breaks AI performance records to rival GPU-led industry appeared first on CryptoSlate.
















{kind=link}