

Key Insights
- OpenServ launched the Bounded Reasoning for Autonomous Inference and Decisions (BRAID) architecture on Aug. 28, 2025.
- BRAID achieved 91% accuracy on the GSM8K reasoning benchmark, lifting GPT-4o from 42% while cutting costs up to 75x. On the Scale MultiChallenge benchmark, applying BRAID to GPT-5-nano raised accuracy from 35.66% to 57.72%, surpassing GPT-5 standard (54.41%) at a 40x lower cost.
- OpenServ allocates 25% of gross platform revenue to buy SERV and burn it, linking unit‑level demand (i.e., agent calls, agentic application subscriptions, usage credits) to onchain supply reduction.
- OpenServ’s most distinctive whitespace is its mix of a developer SDK, no‑code builder, agentic application (aApp) builder, and crypto‑native economics. If BRAID reliably raises baseline performance for complex tasks on cheaper models, it enables single-founder teams to build what previously required VC-scale resources, removes the cost barrier that has limited onchain AI, and broadens access to development.
Primer
OpenServ is an applied AI research lab and infrastructure provider developing the foundations for autonomous agent collaboration. Its platform enables AI agents to work together across different ecosystems through a shared operating, reasoning, and communication layer. This infrastructure supports complex, multi-step problem solving and adaptation, allowing coordinated agent teams to automate workflows across both Web2 and Web3 environments.
At the core of OpenServ’s approach is BRAID, a reasoning framework that replaces ambiguous natural language with structured, diagram-based logic to reduce errors in large language model (LLM) agents. On top of BRAID, the agentic application (aApp) builder provides a drag-and-drop backend for composing agents, tools, and data connectors. This lowers the resource threshold for building AI products, enabling single-founder teams to launch applications that once required VC-scale resources. By combining structured multi-agent logic with interoperability, OpenServ expands the reliability and scope of AI-native use cases for businesses and end users.
OpenServ’s ecosystem combines in-house applications with third-party innovations. A flagship example is dash.fun, a personalized, no-code Web3 dashboard. Built on OpenServ’s technical protocol, dash.fun aims to be a key tool in the emerging decentralized finance artificial intelligence (DeFAI) landscape, making complex DeFi operations accessible to everyday users. Through a partnership with LunarCrush, dash.fun and other OpenServ-powered agents can layer in live social-market data, giving users real-time context inside Telegram mini apps and web interfaces.
The platform’s mission is to make agentic applications a new standard for digital services, empowering anyone to build, fund, and deploy revenue-generating AI agents. By combining no-code creation tools with native integrations into high-traffic channels like Telegram and Base, OpenServ shortens the path from concept to deployment, providing a scalable foundation for the AI-native economy.
Website / X (Twitter) / Discord / Blog
BRAID Architecture Launch
OpenServ released their AI reasoning framework BRAID (Bounded Reasoning for Autonomous Inference and Decisions) on Aug. 28, 2025, following a closed beta in the spring. BRAID introduces a new cognitive layer for LLMs, enabling agents to synthesize and execute formal logic plans rather than relying solely on ambiguous natural language or Chain of Thought (CoT) reasoning.
Technical Approach
BRAID’s defining innovation is its two-stage reasoning process. In the first stage, the agent analyzes a problem and generates a Guided Reasoning Diagram (GRD), a machine-readable flowchart using Mermaid syntax that structures the solution logic. In the second stage, the agent executes the GRD, following clear, deterministic instructions that sharply reduce the risk of hallucinations and logical drift. This approach fundamentally decouples problem understanding from execution, allowing complex, rules-based workflows to be carried out with greater reliability and precision.
BRAID is designed for modular integration. The architecture is compatible with a wide range of foundation models and will power OpenServ’s no-code builder and be an essential part of their agents. Its efficient prompting and formal logic flows enable higher performance per dollar than state-of-the-art models, a critical feature for resource-constrained environments like finance or real-time decision systems, including emerging Web3 use cases.
Performance
Performance metrics reported by OpenServ validate BRAID’s architectural leap. Applying BRAID to GPT-4o raised its accuracy from 42% to 91% on GSM8K, a gold-standard reasoning benchmark. Because BRAID functions as a framework rather than a standalone model, it can be integrated with a range of LLMs, including more economical options like GPT-5 nano, to achieve comparable or superior results. In practice, prices have fallen to as little as 1/75th the cost of top-tier models, improving the cost-efficiency of scalable, production-grade AI deployments.
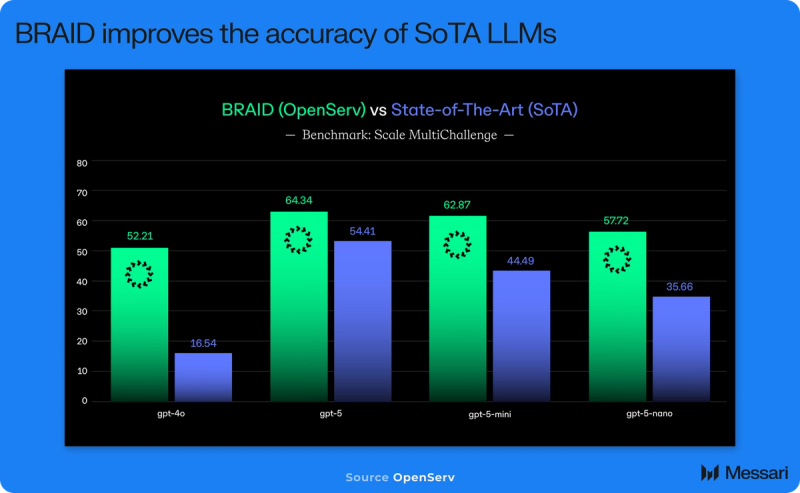
This performance uplift is not limited to GSM8K. According to results reported by OpenServ, BRAID also shows consistent gains on the Scale MultiChallenge benchmark, a 273-question reasoning suite featured in OpenAI’s GPT-5 launch presentation. As shown in the figure above, BRAID improved results across all tested model sizes. For GPT-4o, accuracy rose from 16.54% to 52.21%, more than tripling correct answers. GPT-5’s accuracy increased from 54.41% to 64.34%, GPT-5-mini from 44.49% to 62.87%, and GPT-5-nano from 35.66% to 57.72%. These results suggest that the diagram-first approach can elevate even smaller, lower-cost models into performance ranges typically associated with far larger systems, while preserving the cost and efficiency advantages that make the smaller models viable for production use.
Use Cases
BRAID’s structure is especially suited for business automation, financial operations, dynamic planning, troubleshooting, building AI/AI agent-powered products, and any workflow requiring reliable, rules-based reasoning. Early adopters include founders participating in the OpenServ Appcelerator and select ecosystem partners. OpenServ’s LunarCrush integration shows how external signals feed BRAID-enabled agents in production, with DeFi News on Telegram and dash.fun providing real-time social context that builders can reuse through published templates and guides.
Perpetual Burn Tokenomics
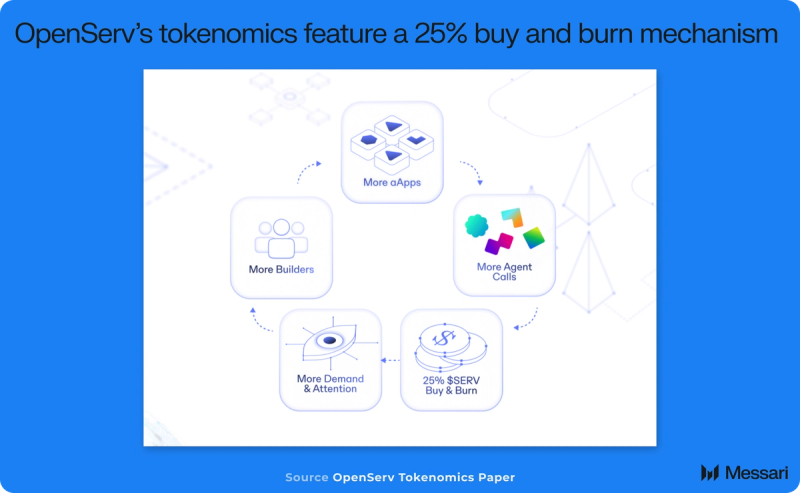
OpenServ allocates 25% of gross platform revenue to buy SERV and burn it, linking unit‑level demand (i.e., agent calls, aApp subscriptions, usage credits) to onchain supply reduction. Revenue is collected in USD credits and automatically converted for buy-and-burn, while builders and contributors receive revenue shares and grants.
Supply Impact
The perpetual burn mechanism is designed to create a deflationary effect on the SERV supply, directly proportional to platform activity and revenue. As adoption increases, more tokens are removed from circulation, creating a supply dynamic that incentivizes both participation and long-term holding.
Incentive Alignment
The buy‑and‑burn mechanic creates a direct link between network effects and token scarcity. Builders are motivated to ship useful aApps, users are motivated to consume, and holders benefit as usage rises. This is similar in spirit to other crypto projects that burn a portion of revenue or fees, though the coupling to agent workload is unique within AI infrastructure.
Comparative Tokenomics
OpenServ’s burn mechanism follows a familiar model: tokens are permanently removed through market buybacks funded by protocol revenue. The key difference is the revenue source. In DeFi and Layer-1s, burns are tied to transaction volume or blockspace demand; in OpenServ’s case, they depend on inference usage and agent output. Burn pace will track adoption of BRAID-enabled agents and trends in model performance and cost, giving SERV holders direct exposure to the growth of the agent economy alongside broader crypto market activity.
Competitive Landscape
The market for autonomous agent infrastructure is rapidly diversifying, with offerings emerging from established cloud providers, decentralized AI networks, and no-code workflow platforms. While these solutions share the goal of enabling more capable systems, they differ in their architectural choices, economic models, and target audiences. OpenServ’s position at the intersection of AI infrastructure, developer tooling, and crypto-native ecosystems means it simultaneously competes across multiple categories.
Enterprise stacks
Amazon Web Services offers supervisor‑and‑collaborator agent trees in Bedrock Agents, while Microsoft’s open‑source AutoGen focuses on multi‑agent negotiation and orchestration. Anthropic has shipped tool use and computer control that push agents into real desktop environments. These platforms compete on capability breadth and rapid feature iteration, though execution still depends primarily on natural language.
Decentralized AI and agent networks
Bittensor incentivizes useful machine intelligence through subnets and TAO rewards. Fetch.ai provides agent frameworks and uAgents in Python. ARC develops infrastructure to support autonomous agents, including transferable learning and deployment tools. Autonolas focuses on co‑owned agent services with OLAS incentives. These ecosystems pursue different slices of the open agent economy, often prioritizing network effects and incentive design over application UX.
No‑code agent builders
Platforms like Lindy, Gumloop, and n8n deliver low-code environments for business process automation, collaboration, and integration. They compete on time‑to‑value and integration breadth rather than on crypto‑native economics or onchain execution.
Whitespace and Threats
OpenServ’s most distinctive whitespace is its mix of a developer SDK, no‑code builder, aApp builder, and crypto‑native economics. If BRAID reliably raises baseline performance for complex tasks on cheaper models, it enables single-founder teams to build what previously required VC-scale resources, removes the cost barrier that has limited onchain AI, and broadens access to development. By embedding agentic applications directly into high-traffic environments like Telegram and Base, the platform increases its distribution reach. However, the competitive landscape is not static; incumbents can incorporate formal planning or neurosymbolic layers quickly, especially as reasoning research advances. If BRAID’s performance uplifts do not generalize beyond curated tasks, the advantage narrows. Decentralized networks could also attract builders with token incentives and liquidity mining for agent services, while no‑code competitors may win on turnkey enterprise adoption.
Feature Benchmarking
The whitespace in this market hinges on delivering reliable reasoning at lower inference cost, supporting rapid deployment, and providing transparency in agent execution. BRAID addresses these points with an explicit, diagram-driven execution model that differs from the linear, natural-language planning used by most competitors. This structure allows agents running on cost-effective models to match or exceed the performance of high-priced incumbents in complex reasoning tasks, narrowing the gap for users priced out of enterprise models.
Cost efficiency is a key differentiator: BRAID-augmented agents can achieve equivalent or better accuracy at a fraction of the cost (75x less for some workloads), mitigating the inference cost pressures that limit many agent startups. Integration benefits include native SDKs, drag-and-drop agent design, and deployment across both cross-chain and social platforms. Deterministic reasoning diagrams and explicit logic flows also enhance trust and auditability, reducing the opacity common in linear or proprietary approaches.
Strategic positioning
OpenServ’s defensibility will hinge on three loops: 1) reproducible gains in reliability from GRD‑first execution, 2) builder economics that convert agent usage into SERV burns, and 3) distribution that captures daily user time inside Telegram and crypto contexts. Success requires maintenance of a strong developer experience and transparent, verifiable token flows.
Conclusion
The launch of BRAID represents a meaningful step-change in the maturation of agentic AI. By improving reasoning reliability, reducing hallucination rates, improving application reliability at scale, lowering inference costs, and introducing auditable execution flows, BRAID sets a new bar for production-ready AI business infrastructure. Coupled with OpenServ’s full-stack platform, community-driven governance, and perpetual burn tokenomics, the release creates a structural foundation for sustainable ecosystem growth and stakeholder alignment.
BRAID’s ability to raise baseline performance on cheaper models lowers the barrier to entry: single-founder teams can now build what once required VC-scale resources, long-standing cost constraints on onchain AI are eased, and a wider pool of developers can participate in building agentic applications. OpenServ’s ability to let builders create and deploy agentic applications in days and embed them directly in high-traffic channels like Telegram and Base app strengthens its claim as core infrastructure for AI-native business creation. The perpetual burn model links platform success to tangible value for SERV holders, reinforcing trust and long-term commitment among ecosystem participants.
Key watchpoints include the scale and velocity of developer adoption, the efficacy of the burn mechanism as mainnet activity ramps, and the company’s ability to defend its whitespace against fast-moving competitors. The next stage will show whether its combination of technical innovation and economic design can secure lasting adoption in a competitive and rapidly evolving agent economy.
















{kind=link}